RGB Image Quality Evaluation on Kodak#
Model |
bpp |
PSNR |
LPIPS (dB) |
DISTS (dB) |
SSIM |
|---|---|---|---|---|---|
LiVeAction f16c12 half res. (LSDIR) |
0.0428 |
24.2336 |
2.7625 |
6.2970 |
0.7194 |
AVIF (q=1) |
0.0419 |
24.4644 |
2.4108 |
5.7843 |
0.7162 |
JPEG 2000 (CR 400:1) |
0.0597 |
23.4048 |
2.1388 |
5.1450 |
0.6378 |
Cosmos di16×16 (Proprietary) |
0.0625 |
21.7743 |
5.3784 |
10.6189 |
0.6449 |
AVIF (q=5) |
0.0615 |
25.4549 |
2.7339 |
6.3296 |
0.7629 |
JPEG 2000 (CR 250:1) |
0.0957 |
24.3492 |
2.4231 |
5.7073 |
0.6842 |
AVIF (q=10) |
0.0916 |
26.5260 |
3.1129 |
6.9885 |
0.8080 |
JPEG 2000 (CR 160:1) |
0.1495 |
25.3227 |
2.7599 |
6.3334 |
0.7324 |
LiVeAction f16c12 (LSDIR) + FLUX |
0.1507 |
23.2454 |
4.5325 |
9.4840 |
0.6429 |
LiVeAction f16c12 (LSDIR) |
0.1496 |
27.0384 |
4.2153 |
8.8654 |
0.8600 |
JPEG 2000 (CR 125:1) |
0.1916 |
25.8947 |
2.9724 |
6.7353 |
0.7586 |
AVIF (q=25) |
0.2316 |
29.5176 |
4.4152 |
9.1244 |
0.9007 |
Balle 2018 Hyperprior (MSE loss) |
0.2110 |
27.2377 |
3.9050 |
7.9973 |
0.8258 |
JPEG 2000 (CR 100:1) |
0.2393 |
26.4546 |
3.1854 |
7.1317 |
0.7829 |
Cosmos di8×8 (Proprietary) |
0.2500 |
25.9193 |
7.7112 |
13.2647 |
0.8558 |
JPEG 2000 (CR 70:1) |
0.3423 |
27.4229 |
3.5425 |
7.7950 |
0.8182 |
LiVeAction f16c48 lambda=0.1 |
0.3992 |
29.8397 |
5.6911 |
12.0727 |
0.9303 |
WIP v4 f8c12 v4 (LSDIR) |
0.5672 |
30.7820 |
6.3120 |
13.3597 |
0.9550 |
JPEG 2000 (CR 40:1) |
0.5985 |
29.1910 |
4.2655 |
9.1768 |
0.8712 |
WIP v5 f16c48 (LSDIR) |
0.6055 |
31.1788 |
6.3174 |
12.6349 |
0.9593 |
WaLLoC f8c12 (LSDIR) |
0.6171 |
30.5576 |
6.5138 |
13.2437 |
0.9501 |
WIP v4 f16c48 (LSDIR) |
0.6183 |
31.0363 |
6.5498 |
13.7678 |
0.9563 |
WIP v3 f16c48 (LSDIR) |
0.6563 |
31.1226 |
6.5346 |
13.6940 |
0.9580 |
WIP v3 ft f16c48 (LSDIR) |
0.6563 |
31.1820 |
6.5599 |
13.7146 |
0.9584 |
LiVeAction f16c48 (LSDIR) |
0.6606 |
31.1669 |
6.5692 |
13.6699 |
0.9571 |
AVIF (q=50) |
0.6838 |
34.4449 |
7.1089 |
12.9916 |
0.9657 |
LiVeAction f16c48 v2 (LSDIR) |
0.6921 |
31.2534 |
6.5843 |
13.7425 |
0.9582 |
WIP v3 wpt f16c48 (LSDIR) |
0.6924 |
31.0584 |
6.5405 |
14.0196 |
0.9567 |
LiVeAction f16c48 EM (LSDIR) |
0.8334 |
31.1914 |
6.8621 |
14.1159 |
0.8434 |
JPEG 2000 (CR 20:1) |
1.1984 |
32.0019 |
5.4387 |
11.3646 |
0.9262 |
AVIF (q=75) |
1.4551 |
38.7760 |
10.1420 |
17.3158 |
0.9856 |
Balle 2018 (Q=8) |
1.6630 |
37.9544 |
9.4908 |
17.5278 |
0.9143 |
WaLLoC f8c48 (LSDIR) |
2.5436 |
37.3370 |
11.674 |
18.2942 |
0.9873 |
AVIF (q=90) |
2.7103 |
41.9932 |
14.7676 |
22.4631 |
0.9932 |
JPEG 2000 (CR 8:1) |
2.9980 |
37.1560 |
8.2494 |
16.1444 |
0.9746 |
LiveAction f8c48 (LSDIR) |
3.7082 |
39.8998 |
14.904 |
24.2401 |
0.9959 |
LiveAction f16c192 (LSDIR) |
3.9126 |
40.2877 |
15.290 |
25.5340 |
0.9962 |
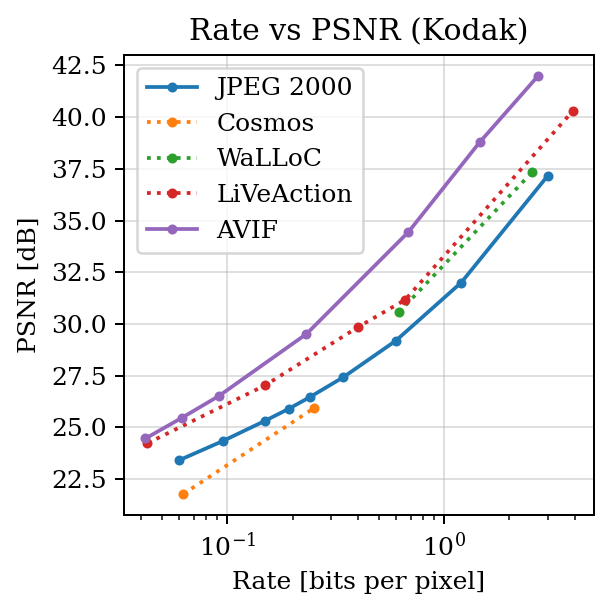
PSNR vs BPP#
import bjontegaard as bd
import matplotlib.pyplot as plt
r_j2k = [0.0597, 0.0957, 0.1495, 0.1916, 0.2393, 0.3423, 0.5985, 1.1984, 2.9980] # bpp
d_j2k = [23.4048, 24.3492, 25.3227, 25.8947, 26.4546, 27.4229, 29.1910, 32.0019, 37.1560] # PSNR
r_avif = [0.0419, 0.0615, 0.0916, 0.2316, 0.6838, 1.4551, 2.7103]
d_avif = [24.4644, 25.4549, 26.5260, 29.5176, 34.4449, 38.7760, 41.9932]
r_cosmos = [0.0625, 0.2500]
d_cosmos = [21.7743, 25.9193]
r_live = [0.04280 , 0.1496, 0.3992, 0.6606, 3.9126]
d_live = [24.234, 27.0384, 29.8397, 31.1669, 40.2877]
r_walloc = [0.6171, 2.5436]
d_walloc = [30.5576, 37.3370]
plt.rcParams["font.family"] = "serif"
plt.figure(figsize=(3.5, 3.5), dpi=180)
plt.semilogx(r_j2k, d_j2k, marker='.', linestyle='-', label='JPEG 2000')
plt.plot(r_cosmos, d_cosmos, marker='.', linestyle=':', label='Cosmos')
plt.plot(r_walloc, d_walloc, marker='.', linestyle=':', label='WaLLoC')
plt.plot(r_live, d_live, marker='.', linestyle=':', label='LiVeAction')
plt.plot(r_avif, d_avif, marker='.', linestyle='-', label='AVIF')
plt.xlabel("Rate [bits per pixel]")
plt.ylabel("PSNR [dB]")
plt.title("Rate vs PSNR (Kodak)")
plt.legend(loc='best')
plt.grid(True, alpha=0.4)
plt.tight_layout()
bd_cosmos = bd.bd_rate(r_j2k, d_j2k, r_cosmos, d_cosmos,
method='pchip', require_matching_points=False, min_overlap=0.15)
bd_live = bd.bd_rate(r_j2k, d_j2k, r_live, d_live,
method='pchip', require_matching_points=False, min_overlap=0.15)
bd_walloc = bd.bd_rate(r_j2k, d_j2k, r_walloc, d_walloc,
method='pchip', require_matching_points=False, min_overlap=0.15)
bd_avif = bd.bd_rate(r_j2k, d_j2k, r_avif, d_avif,
method='pchip', require_matching_points=False, min_overlap=0.15)
print(f"BD-Rate (Cosmos vs JPEG 2000): {bd_cosmos:+.4f} %")
print(f"BD-Rate (WaLLoC vs JPEG 2000): {bd_walloc:+.4f} %")
print(f"BD-Rate (LiVeAction vs JPEG 2000): {bd_live:+.4f} %")
print(f"BD-Rate (AVIF vs JPEG 2000): {bd_avif:+.4f} %")
plt.savefig('rate_psnr.svg')
BD-Rate (Cosmos vs JPEG 2000): +49.6106 %
BD-Rate (WaLLoC vs JPEG 2000): -27.6079 %
BD-Rate (LiVeAction vs JPEG 2000): -36.5547 %
BD-Rate (AVIF vs JPEG 2000): -64.0286 %
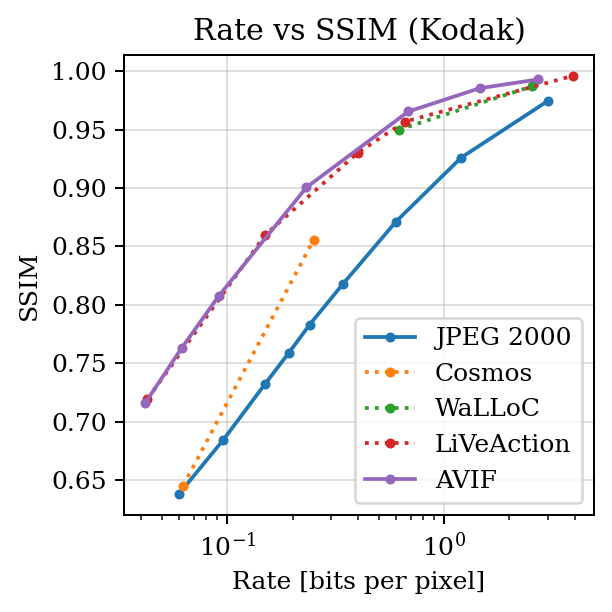
SSIM vs bpp#
import bjontegaard as bd
import matplotlib.pyplot as plt
r_j2k = [0.0597, 0.0957, 0.1495, 0.1916, 0.2393, 0.3423, 0.5985, 1.1984, 2.9980]
d_j2k = [0.6378, 0.6842, 0.7324, 0.7586, 0.7829, 0.8182, 0.8712, 0.9262, 0.9746]
r_avif = [0.0419, 0.0615, 0.0916, 0.2316, 0.6838, 1.4551, 2.7103]
d_avif = [0.7162, 0.7629, 0.8080, 0.9007, 0.9657, 0.9856, 0.9932]
r_cosmos = [0.0625, 0.2500]
d_cosmos = [0.6449, 0.8558]
r_live = [0.04280, 0.1496, 0.3992, 0.6606, 3.9126]
d_live = [0.7194, 0.8600, 0.9303, 0.9571, 0.9962]
r_walloc = [0.6171, 2.5436]
d_walloc = [0.9501, 0.9873]
plt.rcParams["font.family"] = "serif"
plt.figure(figsize=(3.5, 3.5), dpi=180)
plt.semilogx(r_j2k, d_j2k, marker='.', linestyle='-', label='JPEG 2000')
plt.plot(r_cosmos, d_cosmos, marker='.', linestyle=':', label='Cosmos')
plt.plot(r_walloc, d_walloc, marker='.', linestyle=':', label='WaLLoC')
plt.plot(r_live, d_live, marker='.', linestyle=':', label='LiVeAction')
plt.plot(r_avif, d_avif, marker='.', linestyle='-', label='AVIF')
plt.xlabel("Rate [bits per pixel]")
plt.ylabel("SSIM")
plt.title("Rate vs SSIM (Kodak)")
plt.legend(loc='best')
plt.grid(True, alpha=0.4)
plt.tight_layout()
bd_cosmos = bd.bd_rate(r_j2k, d_j2k, r_cosmos, d_cosmos,
method='pchip', require_matching_points=False, min_overlap=0.15)
bd_live = bd.bd_rate(r_j2k, d_j2k, r_live, d_live,
method='pchip', require_matching_points=False, min_overlap=0.15)
bd_walloc = bd.bd_rate(r_j2k, d_j2k, r_walloc, d_walloc,
method='pchip', require_matching_points=False, min_overlap=0.15)
bd_avif = bd.bd_rate(r_j2k, d_j2k, r_avif, d_avif,
method='pchip', require_matching_points=False, min_overlap=0.15)
print(f"BD-Rate (Cosmos vs JPEG 2000): {bd_cosmos:+.4f} %")
print(f"BD-Rate (WaLLoC vs JPEG 2000): {bd_walloc:+.4f} %")
print(f"BD-Rate (LiVeAction vs JPEG 2000): {bd_live:+.4f} %")
print(f"BD-Rate (AVIF vs JPEG 2000): {bd_avif:+.4f} %")
plt.savefig('rate_ssim.svg')
BD-Rate (Cosmos vs JPEG 2000): -29.9439 %
BD-Rate (WaLLoC vs JPEG 2000): -57.5230 %
BD-Rate (LiVeAction vs JPEG 2000): -70.2994 %
BD-Rate (AVIF vs JPEG 2000): -71.0959 %
/home/dgj335/g/lib/python3.12/site-packages/bjontegaard/bjontegaard_delta.py:54: UserWarning: Insufficient curve overlap: '7.01'. Minimum overlap: '15.00'. You can silence this warning by setting `min_overlap=0`
warnings.warn(
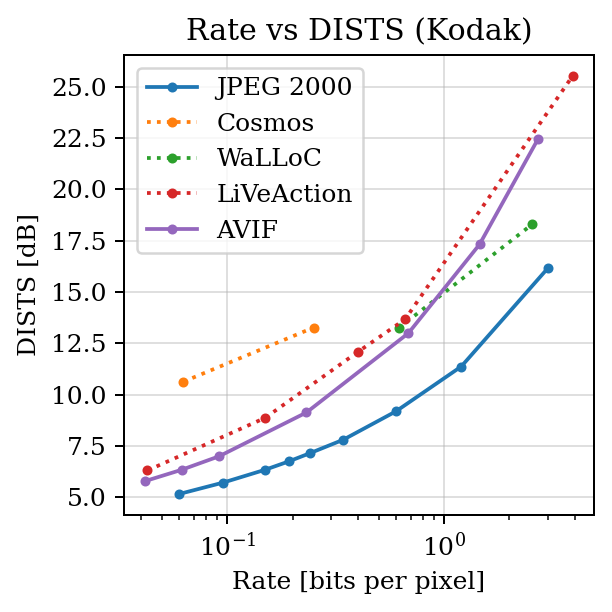
DISTS vs bpp#
import bjontegaard as bd
import matplotlib.pyplot as plt
r_j2k = [0.0597, 0.0957, 0.1495, 0.1916, 0.2393, 0.3423, 0.5985, 1.1984, 2.9980]
d_j2k = [5.1450, 5.7073, 6.3334, 6.7353, 7.1317, 7.7950, 9.1768, 11.3646, 16.1444]
r_avif = [0.0419, 0.0615, 0.0916, 0.2316, 0.6838, 1.4551, 2.7103]
d_avif = [5.7843, 6.3296, 6.9885, 9.1244, 12.9916, 17.3158, 22.4631]
r_cosmos = [0.0625, 0.2500]
d_cosmos = [10.6189, 13.2647]
r_live = [0.04280, 0.1496, 0.3992, 0.6606, 3.9126]
d_live = [6.2970, 8.8654, 12.0727, 13.6699, 25.5340]
r_walloc = [0.6171, 2.5436]
d_walloc = [13.2437, 18.2942]
plt.rcParams["font.family"] = "serif"
plt.figure(figsize=(3.5, 3.5), dpi=180)
plt.semilogx(r_j2k, d_j2k, marker='.', linestyle='-', label='JPEG 2000')
plt.plot(r_cosmos, d_cosmos, marker='.', linestyle=':', label='Cosmos')
plt.plot(r_walloc, d_walloc, marker='.', linestyle=':', label='WaLLoC')
plt.plot(r_live, d_live, marker='.', linestyle=':', label='LiVeAction')
plt.plot(r_avif, d_avif, marker='.', linestyle='-', label='AVIF')
plt.xlabel("Rate [bits per pixel]")
plt.ylabel("DISTS [dB]")
plt.title("Rate vs DISTS (Kodak)")
plt.legend(loc='best')
plt.grid(True, alpha=0.4)
plt.tight_layout()
bd_cosmos = bd.bd_rate(r_j2k, d_j2k, r_cosmos, d_cosmos,
method='pchip', require_matching_points=False, min_overlap=0.15)
bd_live = bd.bd_rate(r_j2k, d_j2k, r_live, d_live,
method='pchip', require_matching_points=False, min_overlap=0.15)
bd_walloc = bd.bd_rate(r_j2k, d_j2k, r_walloc, d_walloc,
method='pchip', require_matching_points=False, min_overlap=0.15)
bd_avif = bd.bd_rate(r_j2k, d_j2k, r_avif, d_avif,
method='pchip', require_matching_points=False, min_overlap=0.15)
print(f"BD-Rate (Cosmos vs JPEG 2000): {bd_cosmos:+.4f} %")
print(f"BD-Rate (WaLLoC vs JPEG 2000): {bd_walloc:+.4f} %")
print(f"BD-Rate (LiVeAction vs JPEG 2000): {bd_live:+.4f} %")
print(f"BD-Rate (AVIF vs JPEG 2000): {bd_avif:+.4f} %")
# plt.show()
plt.savefig('rate_dists.svg')
BD-Rate (Cosmos vs JPEG 2000): -90.8796 %
BD-Rate (WaLLoC vs JPEG 2000): -61.7135 %
BD-Rate (LiVeAction vs JPEG 2000): -70.2706 %
BD-Rate (AVIF vs JPEG 2000): -60.5623 %
Quality evaluation#
import pillow_jpls, torch, io, datasets, PIL.Image, numpy as np
from huggingface_hub import hf_hub_download
from types import SimpleNamespace
from piq import LPIPS, DISTS, SSIMLoss
from livecodec.codec import AutoCodecND, latent_to_pil, pil_to_latent
from torchvision.transforms.v2.functional import to_pil_image, pil_to_tensor, resize
device = "cuda:0"
dataset = datasets.load_dataset("danjacobellis/kodak")
checkpoint_file = hf_hub_download(
repo_id="danjacobellis/liveaction",
filename="lsdir_f8c48.pth"
)
checkpoint = torch.load(checkpoint_file, map_location="cpu",weights_only=False)
config = checkpoint['config']
codec = AutoCodecND(
dim=2,
input_channels=config.input_channels,
J = int(np.log2(config.F)),
latent_dim=config.latent_dim,
encoder_depth = config.encoder_depth,
encoder_kernel_size = config.encoder_kernel_size,
decoder_depth = config.decoder_depth,
lightweight_encode = config.lightweight_encode,
lightweight_decode = config.lightweight_decode,
).to(device).to(torch.float)
codec.load_state_dict(checkpoint['state_dict'])
codec.eval();
lpips_loss = LPIPS().to(device)
dists_loss = DISTS().to(device)
ssim_loss = SSIMLoss().to(device)
/home/dgj335/g/lib/python3.12/site-packages/torchvision/models/_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.
warnings.warn(
/home/dgj335/g/lib/python3.12/site-packages/torchvision/models/_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=VGG16_Weights.IMAGENET1K_V1`. You can also use `weights=VGG16_Weights.DEFAULT` to get the most up-to-date weights.
warnings.warn(msg)
def evaluate_quality(sample, resample_factor=1.0):
img = sample['image']
x_orig = pil_to_tensor(img).to(device).unsqueeze(0).to(torch.float) / 127.5 - 1.0
orig_size = tuple(x_orig.shape[-2:])
new_size = tuple(int(resample_factor*s) for s in (orig_size))
if resample_factor == 1:
x_resize = x_orig
else:
x_resize = resize(x_orig, new_size, interpolation=PIL.Image.Resampling.BICUBIC)
orig_dim = x_orig.numel()
with torch.no_grad():
z = codec.encode(x_resize)
latent = codec.quantize.compand(z).round()
jpls = latent_to_pil(latent.cpu(), n_bits=8, C=3)
buff = io.BytesIO()
jpls[0].save(buff, format='JPEG-LS')
size_bytes = len(buff.getbuffer())
latent_decoded = pil_to_latent(jpls, N=config.latent_dim, n_bits=8, C=3).to(device).to(torch.float)
with torch.no_grad():
x_hat = codec.decode(latent_decoded)
if resample_factor == 1:
x_hat = x_hat.clamp(-1,1)
else:
x_hat = resize(x_hat, orig_size, interpolation=PIL.Image.Resampling.BICUBIC).clamp(-1,1)
x_orig_01 = x_orig / 2 + 0.5
x_hat_01 = x_hat / 2 + 0.5
pixels = img.width * img.height
bpp = 8 * size_bytes / pixels
mse = torch.nn.functional.mse_loss(x_orig_01[0], x_hat_01[0])
PSNR = -10 * mse.log10().item()
LPIPS_dB = -10 * np.log10(lpips_loss(x_orig_01.to("cuda"), x_hat_01.to("cuda")).item())
DISTS_dB = -10 * np.log10(dists_loss(x_orig_01.to("cuda"), x_hat_01.to("cuda")).item())
SSIM = 1 - ssim_loss(x_orig_01.to("cuda"), x_hat_01.to("cuda")).item()
return {
'pixels': pixels,
'bpp': bpp,
'PSNR': PSNR,
'LPIPS_dB': LPIPS_dB,
'DISTS_dB': DISTS_dB,
'SSIM': SSIM,
}
results_dataset = dataset['validation'].map(evaluate_quality)
print("mean\n---")
for metric in [
'pixels',
'bpp',
'PSNR',
'LPIPS_dB',
'DISTS_dB',
'SSIM',
]:
μ = np.mean(results_dataset[metric])
print(f"{metric}: {μ}")
mean
---
pixels: 393216.0
bpp: 3.7081688774956603
PSNR: 39.89983995755514
LPIPS_dB: 14.903740262066846
DISTS_dB: 24.240065005226757
SSIM: 0.9959345410267512
Quality evaluation (AVIF speed=5)#
import pillow_jpls, torch, io, datasets, PIL.Image, numpy as np
from huggingface_hub import hf_hub_download
from types import SimpleNamespace
from piq import LPIPS, DISTS, SSIMLoss
from torchvision.transforms.v2.functional import to_pil_image, pil_to_tensor, resize
device = "cuda:0"
dataset = datasets.load_dataset("danjacobellis/kodak")
lpips_loss = LPIPS().to(device)
dists_loss = DISTS().to(device)
ssim_loss = SSIMLoss().to(device)
/home/dgj335/g/lib/python3.12/site-packages/torchvision/models/_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.
warnings.warn(
/home/dgj335/g/lib/python3.12/site-packages/torchvision/models/_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=VGG16_Weights.IMAGENET1K_V1`. You can also use `weights=VGG16_Weights.DEFAULT` to get the most up-to-date weights.
warnings.warn(msg)
def evaluate_quality(sample, quality=50):
img = sample['image']
x_orig = pil_to_tensor(img).to(device).unsqueeze(0).to(torch.float) / 127.5 - 1.0
buff = io.BytesIO()
img.save(buff, format='AVIF', speed=5, quality=quality)
size_bytes = len(buff.getbuffer())
x_hat = pil_to_tensor(PIL.Image.open(buff))/127.5 - 1.0
x_orig_01 = x_orig.to(device) / 2 + 0.5
x_hat_01 = x_hat.to(device).unsqueeze(0) / 2 + 0.5
pixels = img.width * img.height
bpp = 8 * size_bytes / pixels
mse = torch.nn.functional.mse_loss(x_orig_01[0], x_hat_01[0])
PSNR = -10 * mse.log10().item()
LPIPS_dB = -10 * np.log10(lpips_loss(x_orig_01.to("cuda"), x_hat_01.to("cuda")).item())
DISTS_dB = -10 * np.log10(dists_loss(x_orig_01.to("cuda"), x_hat_01.to("cuda")).item())
SSIM = 1 - ssim_loss(x_orig_01.to("cuda"), x_hat_01.to("cuda")).item()
return {
'pixels': pixels,
'bpp': bpp,
'PSNR': PSNR,
'LPIPS_dB': LPIPS_dB,
'DISTS_dB': DISTS_dB,
'SSIM': SSIM,
}
for q in [1,5,10,25,50,75,90]:
results_dataset = dataset['validation'].map(lambda sample: evaluate_quality(sample,q))
print("mean\n---")
for metric in [
'pixels',
'bpp',
'PSNR',
'LPIPS_dB',
'DISTS_dB',
'SSIM',
]:
μ = np.mean(results_dataset[metric])
print(f"{metric}: {μ}")
mean
---
pixels: 393216.0
bpp: 0.04188198513454861
PSNR: 24.464421570301056
LPIPS_dB: 2.410815155551426
DISTS_dB: 5.784285660888493
SSIM: 0.7162355656425158
mean
---
pixels: 393216.0
bpp: 0.061473422580295145
PSNR: 25.454872846603394
LPIPS_dB: 2.733929899283415
DISTS_dB: 6.3296395983775495
SSIM: 0.7629052077730497
mean
---
pixels: 393216.0
bpp: 0.09160868326822917
PSNR: 26.52597079674403
LPIPS_dB: 3.1128611744245642
DISTS_dB: 6.988502157189369
SSIM: 0.8079975123206774
mean
---
pixels: 393216.0
bpp: 0.2316436767578125
PSNR: 29.51759209235509
LPIPS_dB: 4.415217283147694
DISTS_dB: 9.124383003903551
SSIM: 0.9007065842549006
mean
---
pixels: 393216.0
bpp: 0.6838158501519098
PSNR: 34.44487204154333
LPIPS_dB: 7.108879092097792
DISTS_dB: 12.991638472507153
SSIM: 0.9656630431612333
mean
---
pixels: 393216.0
bpp: 1.455071343315972
PSNR: 38.77602736155192
LPIPS_dB: 10.141976662653851
DISTS_dB: 17.315798910466544
SSIM: 0.9855541735887527
mean
---
pixels: 393216.0
bpp: 2.710291544596354
PSNR: 41.99318985144297
LPIPS_dB: 14.76758098661997
DISTS_dB: 22.463094432829124
SSIM: 0.9931813155611356
test#
import pillow_jpls, torch, io, datasets, PIL.Image, numpy as np
from huggingface_hub import hf_hub_download
from types import SimpleNamespace
from typing import OrderedDict
from piq import LPIPS, DISTS, SSIMLoss
from livecodec.codec import latent_to_pil, pil_to_latent
from attend.asym import ConvND, ConvTransposeND, AsymptoticSphereNorm, GELUTanh, Quantize, VitBlockND
from attend.sep import SpatiotemporallySeparableConvND
from attend.monarch import FactorizedConvND
from torchvision.transforms.v2.functional import to_pil_image, pil_to_tensor, resize
device = "cuda:0"
dataset = datasets.load_dataset("danjacobellis/kodak")
checkpoint_file = hf_hub_download(
repo_id='danjacobellis/storage',
filename='v4_patch8.pth',
)
checkpoint = torch.load(checkpoint_file,weights_only=False)
config = checkpoint['config']
class V4(torch.nn.Module):
def __init__(self, dim, analysis_channels, ps, latent_dim, hidden_dim, decoder_depth, head_dim):
super().__init__()
self.layers = torch.nn.Sequential(
OrderedDict(
[
("analysis_transform", torch.nn.Sequential(
OrderedDict(
[
("spatiotempoal", SpatiotemporallySeparableConvND(dim=dim, ch=analysis_channels, kernel_size=ps, groups=analysis_channels[0], bias=True)),
("channels", FactorizedConvND(dim, in_chs=analysis_channels[-1], out_chs=latent_dim, kernel_size=1, bias=True)),
]
)
)),
("norm", AsymptoticSphereNorm()),
("quantize", Quantize()),
("synthesis_transform", torch.nn.Sequential(
OrderedDict(
[
("nn", torch.nn.Sequential(
ConvND(dim, latent_dim, hidden_dim, kernel_size=1, stride=1, padding=0),
*[VitBlockND(dim, in_channels=hidden_dim, norm_layer=AsymptoticSphereNorm, act_layer=GELUTanh, quant_layer=torch.nn.Identity, head_dim=head_dim, expand_ratio=2, drop_path=0.0)
for _ in range(decoder_depth)],
ConvTransposeND(dim, hidden_dim, analysis_channels[0], kernel_size=ps, stride=ps, padding=0),
)),
]
)
)),
]
)
)
def forward(self, x):
return self.layers(x)
def forward_rate(self, x):
z = self.layers[:3](x)
rate = z.std().log2()
xhat = self.layers[-1](z)
return xhat, rate
def forward_hard_quant(self, x):
with torch.no_grad():
z = self.layers[:2](x).round()
xhat = self.layers[-1](z)
return xhat
model = V4(dim=2, analysis_channels=config.analysis_channels, ps=config.ps, latent_dim=config.latent_dim,
hidden_dim=config.hidden_dim, decoder_depth=config.decoder_depth, head_dim=config.head_dim)
model = model.to(device)
model.load_state_dict(checkpoint['state_dict'])
model.eval()
lpips_loss = LPIPS().to(device)
dists_loss = DISTS().to(device)
ssim_loss = SSIMLoss().to(device)
/home/dgj335/g/lib/python3.12/site-packages/torchvision/models/_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.
warnings.warn(
/home/dgj335/g/lib/python3.12/site-packages/torchvision/models/_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=VGG16_Weights.IMAGENET1K_V1`. You can also use `weights=VGG16_Weights.DEFAULT` to get the most up-to-date weights.
warnings.warn(msg)
def evaluate_quality(sample, resample_factor=1.0):
img = sample['image']
x_orig = pil_to_tensor(img).to(device).unsqueeze(0).to(torch.float) / 127.5 - 1.0
orig_size = tuple(x_orig.shape[-2:])
new_size = tuple(int(resample_factor*s) for s in (orig_size))
if resample_factor == 1:
x_resize = x_orig
else:
x_resize = resize(x_orig, new_size, interpolation=PIL.Image.Resampling.BICUBIC)
orig_dim = x_orig.numel()
with torch.inference_mode():
z = model.layers[0:2](x_resize).round()
jpls = latent_to_pil(z.cpu(), n_bits=8, C=3)
buff = io.BytesIO()
jpls[0].save(buff, format='JPEG-LS')
size_bytes = len(buff.getbuffer())
z = pil_to_latent(jpls, N=config.latent_dim, n_bits=8, C=3).to(device).to(torch.float)
with torch.inference_mode():
x_hat = model.layers[-1](z).clamp(-1,1)
if resample_factor == 1:
x_hat = x_hat.clamp(-1,1)
else:
x_hat = resize(x_hat, orig_size, interpolation=PIL.Image.Resampling.BICUBIC).clamp(-1,1)
x_orig_01 = x_orig / 2 + 0.5
x_hat_01 = x_hat / 2 + 0.5
pixels = img.width * img.height
bpp = 8 * size_bytes / pixels
mse = torch.nn.functional.mse_loss(x_orig_01[0], x_hat_01[0])
PSNR = -10 * mse.log10().item()
LPIPS_dB = -10 * np.log10(lpips_loss(x_orig_01.to("cuda"), x_hat_01.to("cuda")).item())
DISTS_dB = -10 * np.log10(dists_loss(x_orig_01.to("cuda"), x_hat_01.to("cuda")).item())
SSIM = 1 - ssim_loss(x_orig_01.to("cuda"), x_hat_01.to("cuda")).item()
return {
'pixels': pixels,
'bpp': bpp,
'PSNR': PSNR,
'LPIPS_dB': LPIPS_dB,
'DISTS_dB': DISTS_dB,
'SSIM': SSIM,
}
results_dataset = dataset['validation'].map(evaluate_quality)
print("mean\n---")
for metric in [
'pixels',
'bpp',
'PSNR',
'LPIPS_dB',
'DISTS_dB',
'SSIM',
]:
μ = np.mean(results_dataset[metric])
print(f"{metric}: {μ}")
mean
---
pixels: 393216.0
bpp: 0.5672327677408854
PSNR: 30.7819605867068
LPIPS_dB: 6.311978725095866
DISTS_dB: 13.359699326050452
SSIM: 0.9550132875641187
test#
import pillow_jpls, torch, io, datasets, PIL.Image, numpy as np
from huggingface_hub import hf_hub_download
from types import SimpleNamespace
from typing import OrderedDict
from piq import LPIPS, DISTS, SSIMLoss
from livecodec.codec import latent_to_pil, pil_to_latent
from attend.asym import ConvND, ConvTransposeND, AsymptoticSphereNorm, GELUTanh, Quantize, VitBlockND
from attend.sep import SpatiotemporallySeparableConvND
from attend.monarch import FactorizedConvND
from torchvision.transforms.v2.functional import to_pil_image, pil_to_tensor, resize
device = "cuda:0"
dataset = datasets.load_dataset("danjacobellis/kodak")
checkpoint_file = hf_hub_download(
repo_id='danjacobellis/storage',
filename='v5.pth',
)
checkpoint = torch.load(checkpoint_file,weights_only=False)
config = checkpoint['config']
class V5(torch.nn.Module):
def __init__(self, dim, analysis_channels, ps, latent_dim, hidden_dim, decoder_depth, head_dim, near_lossless):
super().__init__()
self.layers = torch.nn.Sequential(
OrderedDict(
[
("analysis_transform", torch.nn.Sequential(
OrderedDict(
[
("spatiotempoal", SpatiotemporallySeparableConvND(dim=dim, ch=analysis_channels, kernel_size=ps, groups=analysis_channels[0], bias=True)),
("channels", FactorizedConvND(dim, in_chs=analysis_channels[-1], out_chs=latent_dim, kernel_size=1, bias=True)),
]
)
)),
("norm", AsymptoticSphereNorm()),
("quantize", Quantize(k=near_lossless)),
("synthesis_transform", torch.nn.Sequential(
OrderedDict(
[
("nn", torch.nn.Sequential(
ConvND(dim, latent_dim, hidden_dim, kernel_size=1, stride=1, padding=0),
*[VitBlockND(dim, in_channels=hidden_dim, norm_layer=AsymptoticSphereNorm, act_layer=GELUTanh, quant_layer=torch.nn.Identity, head_dim=head_dim, expand_ratio=2, drop_path=0.0)
for _ in range(decoder_depth)],
ConvTransposeND(dim, hidden_dim, analysis_channels[0], kernel_size=ps, stride=ps, padding=0),
)),
]
)
)),
]
)
)
def forward(self, x):
return self.layers(x)
def forward_rate(self, x):
z = self.layers[:3](x)
rate = z.std().log2()
xhat = self.layers[-1](z)
return xhat, rate
def forward_hard_quant(self, x):
with torch.no_grad():
z = self.layers[:2](x).round()
xhat = self.layers[-1](z)
return xhat
model = V5(dim=2, analysis_channels=config.analysis_channels, ps=config.ps, latent_dim=config.latent_dim,
hidden_dim=config.hidden_dim, decoder_depth=config.decoder_depth, head_dim=config.head_dim, near_lossless=config.near_lossless)
model = model.to(device)
model.load_state_dict(checkpoint['state_dict'])
model.eval()
lpips_loss = LPIPS().to(device)
dists_loss = DISTS().to(device)
ssim_loss = SSIMLoss().to(device)
/home/dgj335/g/lib/python3.12/site-packages/torchvision/models/_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.
warnings.warn(
/home/dgj335/g/lib/python3.12/site-packages/torchvision/models/_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=VGG16_Weights.IMAGENET1K_V1`. You can also use `weights=VGG16_Weights.DEFAULT` to get the most up-to-date weights.
warnings.warn(msg)
def evaluate_quality(sample, resample_factor=1.0):
img = sample['image']
x_orig = pil_to_tensor(img).to(device).unsqueeze(0).to(torch.float) / 127.5 - 1.0
orig_size = tuple(x_orig.shape[-2:])
new_size = tuple(int(resample_factor*s) for s in (orig_size))
if resample_factor == 1:
x_resize = x_orig
else:
x_resize = resize(x_orig, new_size, interpolation=PIL.Image.Resampling.BICUBIC)
orig_dim = x_orig.numel()
with torch.inference_mode():
z = model.layers[0:2](x_resize).round()
jpls = latent_to_pil(z.cpu(), n_bits=8, C=3)
buff = io.BytesIO()
jpls[0].save(buff, format='JPEG-LS', near_lossless=config.near_lossless)
size_bytes = len(buff.getbuffer())
z = pil_to_latent(jpls, N=config.latent_dim, n_bits=8, C=3).to(device).to(torch.float)
with torch.inference_mode():
x_hat = model.layers[-1](z).clamp(-1,1)
if resample_factor == 1:
x_hat = x_hat.clamp(-1,1)
else:
x_hat = resize(x_hat, orig_size, interpolation=PIL.Image.Resampling.BICUBIC).clamp(-1,1)
x_orig_01 = x_orig / 2 + 0.5
x_hat_01 = x_hat / 2 + 0.5
pixels = img.width * img.height
bpp = 8 * size_bytes / pixels
mse = torch.nn.functional.mse_loss(x_orig_01[0], x_hat_01[0])
PSNR = -10 * mse.log10().item()
LPIPS_dB = -10 * np.log10(lpips_loss(x_orig_01.to("cuda"), x_hat_01.to("cuda")).item())
DISTS_dB = -10 * np.log10(dists_loss(x_orig_01.to("cuda"), x_hat_01.to("cuda")).item())
SSIM = 1 - ssim_loss(x_orig_01.to("cuda"), x_hat_01.to("cuda")).item()
return {
'pixels': pixels,
'bpp': bpp,
'PSNR': PSNR,
'LPIPS_dB': LPIPS_dB,
'DISTS_dB': DISTS_dB,
'SSIM': SSIM,
}
results_dataset = dataset['validation'].map(evaluate_quality)
print("mean\n---")
for metric in [
'pixels',
'bpp',
'PSNR',
'LPIPS_dB',
'DISTS_dB',
'SSIM',
]:
μ = np.mean(results_dataset[metric])
print(f"{metric}: {μ}")
mean
---
pixels: 393216.0
bpp: 0.605483161078559
PSNR: 31.178835531075794
LPIPS_dB: 6.317439249373028
DISTS_dB: 12.63491630770168
SSIM: 0.9592879042029381